重新定义新的结束符, 这样可以让
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15DELIMITER //
CREATE PROCEDURE `add_num`(IN n INT)
BEGIN
DECLARE i INT;
DECLARE sum INT;
SET i = 1;
SET sum = 0;
WHILE i <= n DO
SET sum = sum + i;
SET i = i +1;
END WHILE;
SELECT sum;
END //
DELIMITER ;IN, OUT, INOUT
- IN: 修改该参数
- OUT: 把结果放在该参数中
- INPUT: 既用于存储过程的传入参数, 又可以把结果放在该参数中, 调用者可以得到返回值
流程控制语句
- BEGIN…END
- DECLARE: 声明变量
- SET: 赋值
- SELECT … INTO : 变量赋值
- IF … THEN … ENDIF
- CASE
- LOOP, LEAVE, ITERATE: LEAVE可以理解为break, ITERATE可以理解为continue;
- REPEAT … UNTIL … END REPEAT : 相当于do while
- WHILE … DO … END WHILE: while
存储过程
- 优点:
- 一次编译多次使用.
- 安全, 可以给存储过程设置用户权限
- 可以减少网络传输量
- 缺点:
- 它的可移植性差,存储过程不能跨数据库移植
- 其次调试困难,只有少数 DBMS 支持存储过程的调试, 对于复杂的存储过程来说,开发和维护都不容易。
- 存储过程的版本管理也很困难,比如数据表索引发生变化了,可能会导致存储过程失效。我们在开发软件的时候往往需要进行版本管理,但是存储过程本身没有版本控制,版本迭代更新的时候很麻烦。
- 最后它不适合高并发的场景,高并发的场景需要减少数据库的压力,有时数据库会采用分库分表的方式,而且对可扩展性要求很高,在这种情况下,存储过程会变得难以维护,增加数据库的压力,显然就不适用了。
- 优点:
事务
- START TRANSACTION / BEGIN,作用是显式开启一个事务。
- COMMIT:提交事务。当提交事务后,对数据库的修改是永久性的。
- ROLLBACK / ROLLBACK TO [SAVEPOINT]: 回滚事务/回滚到某个保存点
- SAVEPOINT: 在事务中创建保存点, 方便后续针对保存点进行回滚.
- RELEASE SAVEPOINT:删除某个保存点
- SET TRANSACTION: 设置事务的隔离级别
参数completion_type:
- completion_type = 0,这是默认情况。也就是说当我们执行 COMMIT 的时候会提交事务,在执行下一个事务时,还需要我们使用 START TRANSACTION 或者 BEGIN 来开启。
- completion_type = 1,这种情况下,当我们提交事务后,相当于执行了 COMMIT AND CHAIN,也就是开启一个链式事务,即当我们提交事务之后会开启一个相同隔离级别的事务(隔离级别会在下一节中进行介绍)。
- completion_type = 2,这种情况下 COMMIT=COMMIT AND RELEASE,也就是当我们提交后,会自动与服务器断开连接。
参数autocommit
- autocommit=0, 每条sql语句都会自动进行提交
- autocommit=1, 不论是否采用 START TRANSACTION 或者 BEGIN 的方式来开启事务,都需要用 COMMIT 进行提交,让事务生效,使用 ROLLBACK 对事务进行回滚。
事务隔离异常情况
- 脏读(Dirty Read) : 读到了其他事务还没有提交的数据.
- 不可重复读(Nonrepeatable Read) : 对某数据进行读取,发现两次读取的结果不同,也就是说没有读到相同的内容。这是因为有其他事务对这个数据同时进行了修改或删除。
- 幻读(Phantom Read): 事务 A 根据条件查询得到了 N 条数据,但此时事务 B 更改或者增加了 M 条符合事务 A 查询条件的数据,这样当事务 A 再次进行查询的时候发现会有 N+M 条数据,产生了幻读。
隔离级别, 为了解决上面的三种异常情况
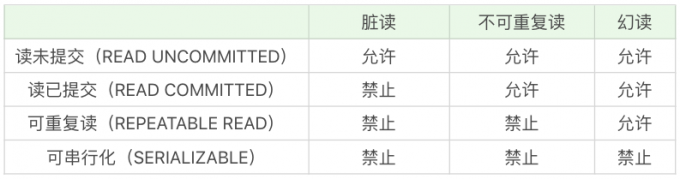
查看隔离级别:
- SHOW VARIABLES LIKE ‘transaction_isolation’;
修改隔离级别:
- SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; (读未提交)
游标: 游标让 SQL 这种面向集合的语言有了面向过程开发的能力。可以说,游标是面向过程的编程方式,这与面向集合的编程方式有所不同。
可以遍历所有数据, 可以让每一个数据进行更改.使用游标: (不用就要释放)
1
2
3
4
5DECLARE cur_hero CURSOR FOR SELECT hp_max FROM heros;
OPEN cursor_name
FETCH cursor_name INTO var_name ...
CLOSE cursor_name
DEALLOCATE cursor_namec效率: SELECT COUNT(*) = SELECT COUNT(1) > SELECT COUNT(具体字段)
如果是 MySQL MyISAM 存储引擎,统计数据表的行数只需要O(1)的复杂度,这是因为每张 MyISAM 的数据表都有一个 meta 信息存储了row_count值,而一致性则由表级锁来保证。因为 InnoDB 支持事务,采用行级锁和 MVCC 机制,所以无法像 MyISAM 一样,只维护一个row_count变量,因此需要采用扫描全表,进行循环 + 计数的方式来完成统计。
如果要统计COUNT(),尽量在数据表上建立二级索引,系统会自动采用key_len小的二级索引进行扫描,这样当我们使用SELECT COUNT()的时候效率就会提升,有时候可以提升几倍甚至更高.
单独的LIKE ‘%’无法查出 NULL 值,比如:SELECT * FROM heros WHERE role_assist LIKE ‘%’。
在 MySQL 中,支持两种排序方式,分别是 FileSort 和 Index 排序。在 Index 排序中,索引可以保证数据的有序性,不需要再进行排序,效率更高。而 FileSort 排序则一般在内存中进行排序,占用 CPU 较多。如果待排结果较大,会产生临时文件 I/O 到磁盘进行排序的情况,效率较低。
所以使用 ORDER BY 子句时,应该尽量使用 Index 排序,避免使用FileSort 排序。当然你可以使用 explain 来查看执行计划,看下优化器是否采用索引进行排序。
数据库复习2
Author: Qin Peng
License: Copyright (c) 2020 BY QPWLKQ LICENSE
Slogan: 每一个不曾起舞的日子, 都是对生命的辜负