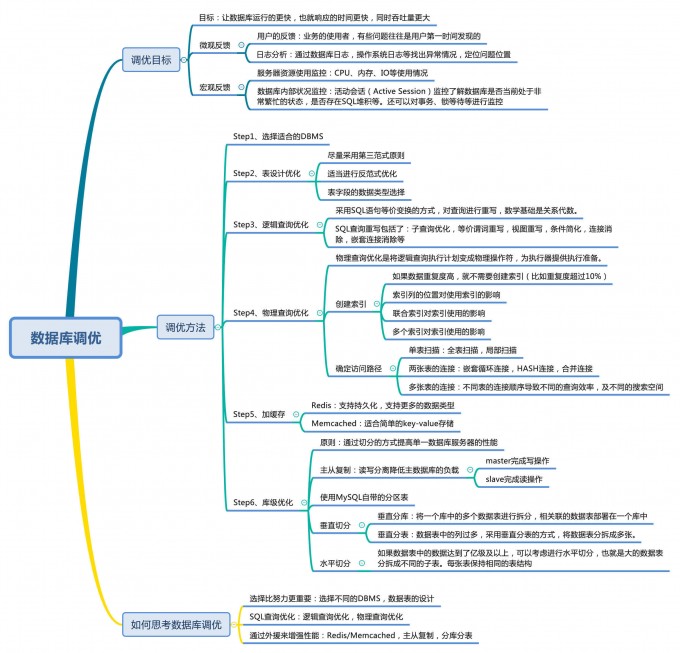
- 选择合适的DBMS
- 优化表结构
- 表结构要尽量遵循第三范式的原则(关于第三范式,我在后面章节会讲)。这样可以让数据结构更加清晰规范,减少冗余字段,同时也减少了在更新,插入和删除数据时等异常情况的发生。
- 如果分析查询应用比较多,尤其是需要进行多表联查的时候,可以采用反范式进行优化。反范式采用空间换时间的方式,通过增加冗余字段提高查询的效率。
- 表字段的数据类型选择,关系到了查询效率的高低以及存储空间的大小。一般来说,如果字段可以采用数值类型就不要采用字符类型;字符长度要尽可能设计得短一些。针对字符类型来说,当确定字符长度固定时,就可以采用 CHAR 类型;当长度不固定时,通常采用 VARCHAR 类型。
- 优化逻辑查询
- 子查询优化
- 等价谓词重写
- 视图重写
- 条件简化
- 连接消除
- 嵌套连接消除
- 优化物理查询: 重点是建立索引的物理优化技术
- 如果数据重复度高,就不需要创建索引。通常在重复度超过 10% 的情况下,可以不创建这个字段的索引。比如性别这个字段(取值为男和女)。
- 要注意索引列的位置对索引使用的影响。比如我们在 WHERE 子句中对索引字段进行了表达式的计算,会造成这个字段的索引失效。
- 要注意联合索引对索引使用的影响。我们在创建联合索引的时候会对多个字段创建索引,这时索引的顺序就很重要了。比如我们对字段 x, y, z 创建了索引,那么顺序是 (x,y,z) 还是 (z,y,x),在执行的时候就会存在差别。
- 要注意多个索引对索引使用的影响。索引不是越多越好,因为每个索引都需要存储空间,索引多也就意味着需要更多的存储空间。此外,过多的索引也会导致优化器在进行评估的时候增加了筛选出索引的计算时间,影响评估的效率。
- 使用外援: Redis, Memcached
- 当我们有持久化需求或者是更高级的数据处理需求的时候,就可以使用 Redis
- 如果是简单的 key-value 存储,则可以使用 Memcached。
- 通常我们对于查询响应要求高的场景(响应时间短,吞吐量大),可以考虑内存数据库,毕竟术业有专攻。
- 库级优化
- 控制一个库中的数据表数量
- 如果读和写的业务量都很大并且它们都在同一个数据库服务器中进行操作,那么数据库的性能就会出现瓶颈,这时为了提升系统的性能,优化用户体验,我们可以采用读写分离的方式降低主数据库的负载,比如用主数据库(master)完成写操作,用从数据库(slave)完成读操作。
- 我们还可以对数据库分库分表, 当数据量级达到亿级以上时,有时候我们需要把一个数据库切成多份,放到不同的数据库服务器上,减少对单一数据库服务器的访问压力。如果你使用的是 MySQL,就可以使用 MySQL 自带的分区表功能,当然你也可以考虑自己做垂直切分和水平切分。
- 如果表过多/如果数据表中的列过多,可以采用垂直分表的方式,将数据表分拆成多张,把经常一起使用的列放到同一张表里。
- 可以考虑水平切分,将大的数据表分拆成不同的子表,每张表保持相同的表结构。
- 但需要注意的是,分拆在提升数据库性能的同时,也会增加维护和使用成本。
- 其他
- 利用宏观的监控工具和微观的日志分析可以帮我们快速找到调优的思路和方式。
- 利用宏观的监控工具和微观的日志分析可以帮我们快速找到调优的思路和方式。
数据库调优
Author: Qin Peng
License: Copyright (c) 2020 BY QPWLKQ LICENSE
Slogan: 每一个不曾起舞的日子, 都是对生命的辜负