索引是啥?
索引就是帮助数据库管理系统高效获取数据的数据结构。
索引
通过功能逻辑分:
- 普通索引
- 唯一索引: 普通索引 + 唯一性约束
- 主键索引: 唯一索引 + NOT NULL + UNIQUE, 最多一个
- 全文索引: 只支持英文
通过物理实现分:
- 聚集索引: 聚集索引可以按照主键来排序存储数据,这样在查找行的时候非常有效, 找到了索引的位置,在它后面就是我们想要找的数据行. 一个表最多一个
- 非聚集索引(二级索引/辅助索引): 系统会进行两次查找,第一次先找到索引,第二次再通过聚集索引找到对应的位置取出数据行, 也称回表。非聚集索引不会把索引指向的内容像聚集索引一样直接放到索引的后面,而是维护单独的索引表(只维护索引,不维护索引指向的数据)
- 对比:
- 聚集索引的叶子节点存储的就是我们的数据记录,非聚集索引的叶子节点存储的是数据位置。非聚集索引不会影响数据表的物理存储顺序。
- 一个表只能有一个聚集索引,因为只能有一种排序存储的方式,但可以有多个非聚集索引,也就是多个索引目录提供数据检索。
- 使用聚集索引的时候,数据的查询效率高,但如果对数据进行插入,删除,更新等操作,效率会比非聚集索引低。
通过字段个数分:
- 单一索引: 索引列为一列时为单一索引.
- 联合索引: 多个列组合在一起创建的索引.
- 最左匹配原则: (很像结构体排序), 详见文章: 数据库复习1
- 覆盖索引: 详见文章: 数据库复习1
平衡二叉搜索树(AVL树), B树, B+树
B树 和 B+ 树的区别!
- 有 k 个孩子的节点就有 k 个关键字。也就是孩子数量 = 关键字数,而 B 树中,孩子数量 = 关键字数 +1
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而 B 树中,非叶子节点既保存索引,也保存数据记录
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接
- 不仅是对单个关键字的查询上,在查询范围上,B+ 树的效率也比 B 树高。这是因为所有关键字都出现在 B+ 树的叶子节点中,并通过有序链表进行了链接。而在 B 树中则需要通过中序遍历才能完成查询范围的查找,效率要低很多.
为什么不用平衡二叉树:
虽然传统的二叉树数据结构查找数据的效率高,但很容易增加磁盘 I/O 操作的次数,影响索引使用的效率。因此在构造索引的时候,我们更倾向于采用“矮胖”的数据结构。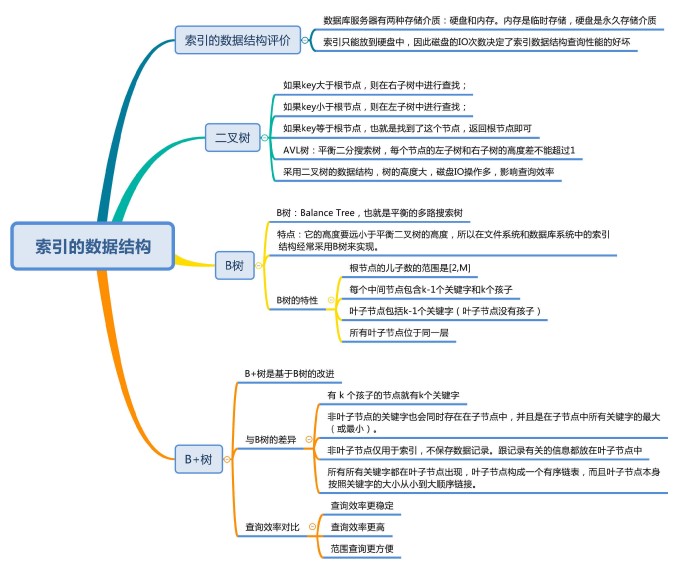
什么时候可以创建索引?
- 字段的数值有唯一性的约束, 可以创建唯一索引或者主键索引
- 频繁作为where 查询条件的字段吗, 可以创建普通索引
- 需要经常使用GROUP BY或者ORDER BY的列
- 实际上多个单列索引在多条件查询时只会生效一个索引(MySQL 会选择其中一个限制最严格的作为索引),所以在多条件联合查询的时候最好创建联合索引
- DISTINCT 字段需要创建索引
- 做多表 JOIN 连接操作时,创建索引需要注意以下的原则
什么时候不用创建索引
- where/group by/order by涉及不到的列, 不用建立索引
- 行数比较少的情况下,比如不到 1000 行,是不需要创建索引的.
- 当数据重复度大,比如高于 10% 的时候,也不需要对这个字段使用索引. (特殊情况: 女儿国, 查找男性数量的索引会很快, 我们不仅要看字段中的数值个数,还要根据数值的分布情况来考虑是否需要创建索引)
- 频繁更新的字段不一定要创建索引。因为更新数据的时候,也需要更新索引,如果索引太多,在更新索引的时候也会造成负担,从而影响效率。
什么情况下索引会失效?
- 如果索引了表达式计算, 就会失效. 因为要取出数据进行计算才能判断, 所以会变成全表扫描.
- 如果对索引使用函数, 也会造成失效
- 在 WHERE 子句中,如果在 OR 前的条件列进行了索引,而在 OR 后的条件列没有进行索引,那么索引会失效。因为 OR 的含义就是两个只要满足一个即可,因此只有一个条件列进行了索引是没有意义的,只要有条件列没有进行索引,就会进行全表扫描,因此索引的条件列也会失效.
- 当我们使用 LIKE 进行模糊查询的时候,前面是’%’, 也会失效
- 索引列尽量设置为 NOT NULL 约束, 判断索引列是否为 NOT NULL,往往需要走全表扫描,因此我们最好在设计数据表的时候就将字段设置为 NOT NULL 约束比如你可以将 INT 类型的字段,默认值设置为 0。将字符类型的默认值设置为空字符串 (‘’).
- 我们在使用联合索引的时候要注意最左原则, 不然就会失效.