[toc]
一点散的知识
默认端口号: 6379
why? 6379在是手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字。MERZ长期以来被Redis作者antirez及其朋友当作愚蠢的代名词。后来Redis作者在开发Redis时就选用了这个, 总之就是大佬自己乐意.
默认16个数据库, 类似数组下标从0开始, 默认用0号库, 共用相同密码
注意redis是不遵循标准SQL的.
redis是单线程 + 多路IO复用技术
redis与memecached不同:
- redis支持多种数据类型
- redis支持持久化
- redis实现方式是单线程+IO复用, memcached用的是多线程+锁
select NUM: 切换库dasize: 查看当前数据库key的数量flushdb: 清空当前库flushall: 通杀全部库
关于键key的基本操作
大写KEY是要进行操作的键名
set KEY VALUE: 设置键值对, 对key重复设置value会覆盖keys *: 查看当前库所有key, 也可以模糊匹配:keys k*, 查看所有k开头的键.exists KEY: 查询某key受否存在, 存在返回1, 否则返回0type KEY: 查看某个key的类型del KEY: 立刻删除某个key, 成功返回1, 不存在返回0.unlink KEY: 根据value选择非阻塞删除, 仅将key从keyspace元数据中删除, 真正的删除会在后续异步删除.expire KEY SECONDS: 设置key的过期时间ttl KEY: 查看key还有多久过期, -1表示永不国企, -2表示已经过期(没有这个key也是-2), >= 0就表示还有多少秒过期
五大数据类型
1. 字符串 String
基本介绍
- 可以理解成与memacached一模一样的类型, 一个key对应一个value
- String类型是二进制安全的, 意味着它可以包含任何数据, 比如jpg图片或者序列化的对象, 只要能变成一个字符串就能存进去.
- 一个Redis中字符串value最大是512MB
常用命令
get KEY: 取值append KEY: 追加到value后, 返回value长度(改后)strlen KEY: 获取value的长度setnx KEY VALUE: 只有key不存在的时候, 才能设置, 成功返回1, 失败返回0incr KEY: 将key中存储的数字值(value)+1, 返回value.decr KEY: 将key中存储的数字值(value)-1, 返回value.incrby/decrby KEY 步长: 将key中存储的数字值(value)+/-步长, 返回value, 它是原子操作, 所谓原子操作是指不会被线程调度机制打断的操作.mset KEY1 VALUE1 KEY2 VALUE2 ...: 设置多个键值对.mget KEY1 KEY2 KEY3 ...: 获取多个key的value.msetnx: 设置多个键值对, 类似setnx, 但是如果有一个不成功(重复设置), 所有的都不会被设置.getrange KEY START END: 获取范围值[START, END]setrange KEY OFFSET VALUE: 从第OFFSET位置用VALUE值覆盖原value, 非常灵活, 测试了一下, 甚至可以超出当前的长度, 中间的未设置的位置被填充为’/00’.setex KEY TIME VALUE: 设置键值对的同时, 设置过期时间.getset KEY VALUE: 设置了新值, 同时获取旧值
String 底层实现
简单动态字符串(Simple Dynamic String).
是可以修改的字符串, 内部结构实现上类似Java的ArrayList, 采用分配冗余空间的方式来减少内存的频繁分配.
当字符串长度小于1M时, 倍增方式扩容, 但是如果超过1M, 每次扩容1M.
2. 列表 List
基本介绍
类似双向链表, 对两端操作性能高, 对索引下标操作中间的节点性能较差.
常用命令
有的l表示list, 有个l表示left左边, 没有r的别自己造, 没有的事.
lpush/rpush KEY VALUE1 VALUE2: 从左边/右边添加一个或多个值, 注意下标的变动, value可重复lrange KEY START STOP: 按照索引下标获得元素, 从左到右, STOP设为-1, 表示右边第一个value(就是最后一个)lpop/rpop KEY: 从左边/右边取出来一个值.rpoplpush KEY1 KEY2: 从KEY1列表右边取出一个, 插到KEY2列表左边.lindex KEY INDEX: 根据索引下标获取单个元素llen: 获取列表长度linsert KEY before/after VALUE NEWVALUE: 在VALUE的前面/后面插入NEWVALUE. 从0开始扫, 扫到第一个VALUE执行后停止, 多个相同的VALUE不会都被加NEWVALUE.lrem KEY N VALUE: 从左边删除N个VALUE(不够N个也没事), 返回删除了几个.lset KEY INDEX VALUE: 将列表KEY下标为INDEX的值替换成VALUE.
List 底层实现
快速链表quicklist.
首先在列表元素比较少的时候, 会使用一块连续的内存存储, 它将所有的元素紧挨着存储, 这个结构是ziplist, 压缩列表.
当数据比较多的时候, 多个ziplist用链表形式组合起来, 形成quicklist. 也就是说每个ziplist才有两个个额外的指针prev和next, 大大节省空间
3. 集合 Set
基本介绍
- 跟list的区别:
- 无序
- 自动去重
- 它底层是一个value为null的hash表, 所以添加, 删除, 查找的复杂度都是O(1).
基本命令
sadd KEY VALUE1 VALUE2 ...: 将一个或多个member元素加入到集合key中, 已经存在的member元素将被忽略(不是失败, 和msetnx不一样哦)smembers KEY: 取所有值sismember KEY VALUE: 判断KEY是否含有该VALUE值, 有返回1, 没有返回0scard KEY: 返回该集合的元素个数srem KEY VALUE1 VALUE2 ...: 删除集合中的某些元素, 返回成功删除掉的元素的数量spop KEY: 随机吐出一个值, 吐出来就没了srandmember KEY N: 随机取出N个值, 集合里还有, 不是删除smove SOURCE DESTINATION VALUE:将一个集合中一个值挪到另一个集合sinter KEY1 KEY2: 返回两个集合的交集元素sunion KEY1 KEY2: 返回两个集合的并集sdiff KEY1 KEY2: 返回两个集合的差集(KEY1中有的, KEY2中没有的)
Set 底层实现
dict字典, intset/hashtable实现
所有的value 指向同一个内部值
4. 哈希 Hash
基本介绍
hash是一个key-value.
hash是一个string类型的field和value的映射表, 特别适合存储对象. 类似java中的Map<String, Object>
value是一个映射关系, 套娃, 你搁这搁这呢
基本命令
hset KEY FIELD VALUE: 给KEY集合中的FIELD赋值VALUEhget KEY FIELD: 从KEY集合取出VALUEhmset KEY1 FIELD1 VALUE1 ...: 批量设置hexists KEY FIELD: 查看哈希表中, 给定FIELD是否存在hkeys KEY: 查看该hash集合所有的fieldhvals KEY: 查看该hash集合所有的valuehincrby KEY FIELD INCREMENT: 为哈希表key中的域FIELD的值value + INCREMENThsetnx KEY FIELD VALUE: 将key中的FIELD的值value设为VALUE, 且当该FIELD不存在.
Hash 底层实现
Hash对应的数据结构有两种:ziplist(压缩列表), hashtable(哈希表). 当field-value长度较短且个数较少的时候使用ziplist, 否则使用hashtable.
5. 有序集合 Zset
基本介绍
Zset是没有重复元素的字符串集合
每个成员关联了一个评分(score). 这个评分被用来从最低分到最高分(从小到大)排序集合中的成员, 集合中的成员是唯一的, 但是评分是可以重复的.
基本命令
zadd KEY SCORE1 VALUE1 SCORE2 VALUE2 ...: 将一个或多个元素及其评分加入到KEY集合中.zrange KEY MIN MAX [withscores]: 返回 MIN <= score <= MAX的成员, MAX是 -1 表示最大值, 可选参数withscores: 返回元素及其scorezrangebyscore KEY MIN MAX [withscores] [limit offset count]: 从小到大排序zrevrangebyscore KEY MAX MIN [withscores] [limit offset count]: 从大到小排序, MAX和MIN写反了结果不一样的.zincrby KEY INCREMENT VALUE: 为元素的score加上增量zrem KEY VALUE: 删除该集合指定值的元素zcount KEY MIN MAX: 计数,MIN <= score <= MAX的元素有几个zrank KEY VALUE: 返回该值在集合中的排名, 从0开始的
Zset 底层实现
how?
hash表, hash的field = value, hash的value = score
跳跃表, 目的在于给元素value排序, 根据score的范围获取元素列表.
对于有序集合的底层实现, 可以用数组, 平衡树, 链表等, 各有各的优点, 又有个的缺点.
跳跃表的效率堪比红黑树, 实现远比红黑树简单
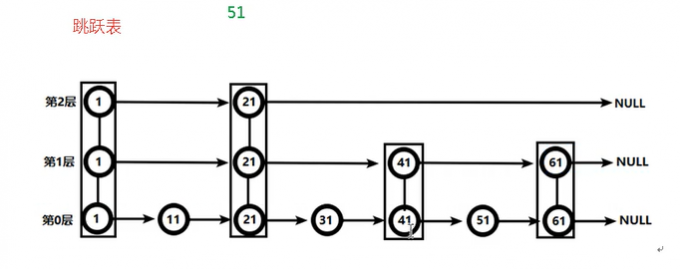
看样子相当费空间